|
|
PureBasic
Survival Guide XV - Regular Expressions
|
A programmer faces a problem. So she teaches herself regular expressions. Now she has to face two problems. :-) The above phrase I spotted somewhere on the InterNet. It's a bit unfair, but also a bit true. Although regular expressions can be immensely powerful and effective, they can also be the cause of serious problems, and are certainly not an universal solution to any and all problems. Consider them yet another tool in the programmers' toolbox, powerful yet sharp... Mind your fingers! (As usual I document these things whilst trying to learn and understand them. So these pages could show some irregularities as well as a definite non-structural approach. Gotta' love the web and my sense of direction :-)) Are regular expressions difficult? Well... that depends. Are they useful? Well... that depends as well. Regular expressions can cause many problems, but they also provide opportunities. They are yet another tool in our programmer's toolbox, so it's wise to know a litte about them. Regular expressions allow us to build filters, with which we can test strings for certain conditions, and retrieve parts of those strings. It's even possible to do conversions etc. on the fly, but that's beyond my limited understanding. (Scourge the web, young padawan, scourge the web...) In no way can I be as thorough or complete or even remotely knowledgable as some of the gurus on the Internet. In case you know you won't be impressed with my explanation of regular expressions you might try the following links before continueing with my attempt...
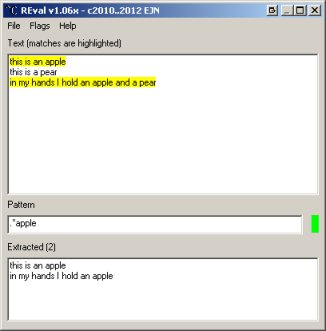
Step one is create a regular expression: ; survival guide 15_2_100 create regexpIn PureBasic first create a rule, and assign a number to it. Then test the string against that rule by using the number. So, if you use the same rule many times, you only have to create it once. In the example above expression 1 is used more than once, as is expression 2. CreateRegularExpression supports using #PB_Any, so it's easy to create and delete an expression if you only need it once: ; survival guide 15_2_200 create regexpSo we now know how to 'create and use' regular expressions, but we still don't know how to build them... That's what the rest of this page is about. Indeed, there's only 20 odd lines or so of actual PureBasic on this page... A regular expression follows its own syntax, it's a kind of language by itself. To simplify experimenting, I've put a little tool on this site called REval. It helps you quickly fooling around with regular expressions without having to modify and execute PureBasic code. You can find it here.
Of course, I'm not the only one who wrote such a thing. Here's another one called RexMan and of course also written in PureBasic. (I totally overlooked it, and probably wouldn't have build my own had I known / remembered :-)) There are definitely some differences between the different regular expression engines out in the world. If you use some external tool to piece together a (complex) regular expression, then be sure to test it within PureBasic. Let's start with building a very simple regular expression: (in the remainder of this page I'll mark the regular expressions themselves in a different colour) aWhen matching 'appel' against the regular expression 'a' we'll find a match. Somewhere in the string we tested ('appel') we found the regular expression ('a'). It didn't matter what was left or right of the 'a'. Obviously 'Appel' did not contain a lowercase 'a' so that did not result in a match. 'appelboom' contains an 'a' so that's a match as well. Of course we can test against more than just a single character: boomOnly 'appleboom' contains 'boom', so only that one returns a match. Some characters have a special meaning, either inside or outside a 'class'. These characters are called 'metacharacters'. More about classes later, for now just consider 'classes' anything between square brackets '[' and ']'. [ \ ^ $ . | ? * + ( )If any of these characters is part of a regular expression it tells the system to do 'something', but it's not going to treat them as if they were normal characters. If you want to use any of these characters as 'normal text' you have to preceed them with a backslash '\'. For example, if you want to look for each occurence of the word 'apple' followed by a question mark, you would have to build your regular expression like this: appel\?If you would not do so, the question mark would be treated much differently, and the outcome would then be: appel?Clearly not the same thing :-) The 'escape' character '\' is not only used in combination with metacharacters, it can also be used to generate 'special' characters. \t - tab, chr(9)There are more special characters than the above, each with their own meaning. Besides the metacharacters (which have now been mentioned so often I'm no longer going to use single quotes around them :-)) there's also the legendary dot, which stands for any single character: . - any single character Instead of matching a specific character we could also match against a selection of characters, also called a 'class'. In the example above we could see that regular expressions are case sensitive. So let's build a regular expression that would match 'appel' as well as 'Appel': [aA]ppelSo, using the square brackets we defined what characters we would accept at that position in the string. We could specify a collection of single characters, or one or more ranges using the dash '-': [Aa-z]ppelSome characters need to be escaped first when they are used inside a class ie. inside square brackets. These are: ^ \ ] -You do not have to escape the other metacharacters (again that word :-)) inside a class. If you want to explicitly exclude a character, you have to preceed it with a caret '^'. So, summarizing: a class is a group of characters enclosed by square brackets, ranges can be specified by using '-', each character or range inside the brackets is a valid match. Here are some examples:
[ab] - single character, either 'a' or 'b' [^a] - any single character except 'a' [0-9] - single character 0 to 9 [0-9A-F] - single hexadecimal character c[ao]t - matches 'cat' and 'cot' but not 'cit' or 'ct' Metacharacters pretty much do nothing by themselves, but they modify the behaviour of other characters. [ \ ^ $ . | ? * + ( )If you want to use a metacharacter as a 'literal' you need to 'escape' it (preceed it with a backslash): cats|dogs - matches 'cats' or 'dogs'Metacharacters are treated differently Inside square brackets (ie. inside classes) and outside. Inside square brackets you do not have to escape any metacharacters except ^ \ ] - [1\-2] - matches '1' '2' and '-' A class stands for a single character. A regular expression such as: [A-F0-9][A-F0-9]... would match anything that contains two hexadecimal characters directly next to each other (ie. 00 to FF). Let's test that: [A-F0-9][A-F0-9]Let's say we would like to find anything containing 'apple' followed by a single hexadecimal character, followed by 'boom' we could use something like: appel[0-9A-F]boomIf we'd like to make the hexadecimal part optional, simply add a '?' sign. It tells the system that the preceeding character or class is optional, ie. it may not exist, or exist one time: appel[0-9A-F]?boomSpecifying all possible characters may be a bit cumbersome if any character would be good, in those cases a simple dot '.' will do. appel.?boomWe can not only specify if, but also how many times a character (or class) may or must occur: appel.boom - anything only onceWe now have multiple options to expand or limit our selection. Summarizing: ^ - anything but the specified characterNote: wildcards '*' and '+' are 'greedy', that is they will grab as much as they can unless that would invalidate a match. (Greedy and lazy and other options are beyond the scope of this explanation, sorry. Check the web for more.) () - groups a part of the expressionGrouping allows you to build more complex, or better readable expressions. (More on alternatives using the pipe '|' character you'll find here.) get(value)? - matches 'get' as well as 'getvalue' Some metacharacters and some special codes allow us to specify the start or end of the string to match. Using the caret '^' outside the class brackets we refer to the start of a string. If our string must start with 'boom' we can use: ^boomNote that the caret '^' inside a class has a different meaning! Here are some examples and variations of codes that define a 'position': ^ - outside brackets! start of the string Classes allow multiple options for a single character, or in combination with a wildcard multiple occurancies of that character. You can also specify complete words or expressions as alternatives: big(cat|dog)Use brackets to control what is part of each 'alternative': bigcat|dog - either 'bigcat' or 'dog'I find the placement of brackets, when using alternatives, a little confusing sometimes (and often a cause for errors). |


|
|